XML DOM - Navigating Nodes


Nodes can be navigated using node relationships.
Examples
The examples below use the XML file
books.xml.
A function, loadXMLDoc(), in an external JavaScript is used to load the XML file.
Get the
parent of a node
This example uses the parentNode property to get the parent of a node
Get the
first child element of a node
This example uses the firstChild() method and a custom function to get the first
child node of a node
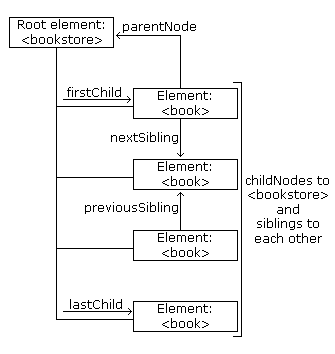
Navigating DOM Nodes
Accessing nodes in the node tree via the relationship between nodes, is often
called "navigating nodes".
In the XML DOM, node relationships are defined as properties to the nodes:
- parentNode
- childNodes
- firstChild
- lastChild
- nextSibling
- previousSibling
The following image illustrates a part of the node tree and the
relationship between nodes in books.xml:
DOM - Parent Node
All nodes has exactly one parent node. The following code navigates to the
parent node of <book>:
xmlDoc=loadXMLDoc("books.xml");
x=xmlDoc.getElementsByTagName("book")[0];
document.write(x.parentNode.nodeName);
|
Example explained:
- Load "books.xml"
into xmlDoc using loadXMLDoc()
- Get the first <book> element
- Output the node name of the parent node of "x"
Try it
yourself
Avoid Empty Text Nodes
Firefox, and some other browsers, will treat empty white-spaces or new lines
as text nodes, Internet Explorer will not.
This causes a problem when using the properties: firstChild, lastChild,
nextSibling, previousSibling.
To avoid navigating to empty text nodes (spaces and new-line characters
between element nodes), we use a function that checks the node type:
function get_nextSibling(n)
{
y=n.nextSibling;
while (y.nodeType!=1)
{
y=y.nextSibling;
}
return y;
}
|
The function above allows you to use get_nextSibling(node) instead of
the property node.nextSibling.
Code explained:
Element nodes are type 1. If the sibling node is not an
element node, it moves to the next nodes until an element node
is found. This way, the result will be the same in both Internet Explorer and
Firefox.
Get the First Child Element
The following code displays the first element node of the first <book>:
<html>
<head>
<script type="text/javascript" src="loadxmldoc.js">
</script>
<script type="text/javascript">
//check if the first node is an element node
function get_firstChild(n)
{
y=n.firstChild;
while (y.nodeType!=1)
{
y=y.nextSibling;
}
return y;
}
</script>
</head>
<body>
<script type="text/javascript">
xmlDoc=loadXMLDoc("books.xml");
x=get_firstChild(xmlDoc.getElementsByTagName("book")[0]);
document.write(x.nodeName);
</script>
</body>
</html>
|
Output:
Example explained:
- Load "books.xml"
into xmlDoc using loadXMLDoc()
- Use the get_firstChild fucntion on the first <book> element node
to get the first child node that is an element node
- Output the node name of first child node that is an element node
Try it
yourself
Examples
The following examples use a similar function:
firstChild:
Try it
yourself lastChild:
Try it
yourself
nextSibling:
Try it
yourself previousSibling:
Try it
yourself
Learn how your website performs under various load conditions
 |
|
WAPT
is a load, stress and performance testing tool for websites and web-based applications.
In contrast to "800-pound gorilla" load testing tools, it is designed to minimize the learning
curve and give you an ability to create a heavy load from a regular workstation.
WAPT is able to generate up to 3000 simultaneously acting virtual users using standard hardware configuration.
Virtual users in each profile are fully customizable. Basic and NTLM authentication methods are supported.
Graphs and reports are shown in real-time at different levels of detail, thus helping to manage the testing process.
Download the free 30-day trial!
|
|